
Optimizing with Bitwise operations
Recently, I was brushing up my data structures and algorithm problem-solving skills and came across this particular problem. It seems fairly straightforward; we just need to check if all 26 alphabets has been encountered in a given string where only lowercase letters are a valid input.
Initial Solution
My initial solution was to use a Set data structure, and add all the characters of the string into the set. Since a Set will eliminate duplicates, we can be sure that it only tracks the presence of the letter.
After iterating through the string, if the size of the set is 26, then we have encountered all alphabets. If it is less than 26, there are letters missing. (Note that in this particular question, only lowercase alphabets are considered as valid input)
Full code:
#include <unordered_set>bool checkIfPangram(std::string sentence) { std::unordered_set<char> charSet; for (char c : sentence) { charSet.insert(c); } return charSet.size() >= 26;}
This solution has a time complexity of O(n) and a space complexity of O(1), since we iterate through the string once and use a Set whose size will be at most 26 entries. Theoretically, this is as good as it gets. What about practically? Are we able to optimize it further?
Further Optimization
The answer to this question was to use a bitmask. A bitmask is a value which encodes certain information in the form of 0's and 1's, and in this case a boolean for the presence of a particular letter. Thus, we can have an integer (Assuming it is 4 bytes -> 32 bits), and use 26 of its bits to record our information.
We can follow this simple rule: 'a' sets bit number 0 (LSB), 'b' sets bit number 1, etc. There are some implementation details we have to consider as well: How are we going to set the bits? Turns out there is a really easy trick to set the bitmask based on our character:
bitmask |= 0x1 << (c-'a');// Note that c is our character of interest.
There is quite a bit to unpack here. First, the rightmost expression c-'a' gets the corresponding bit index of our character. Subtracting 'a' from our char c essentially performs a subtraction on the ASCII values of our characters. Thus, we get a result value of 0 for c = 'a', 1 for c = 'b', and so on.
Next, we perform a leftshift of the number 0x1 with this result value. If the character is 'b', then we will left shift by one, giving us 0x2 or 10 in binary. This operand will be used to set the bit of interest.
Afterwards, we perform an OR operation with our current bitmask with this result and assign the result back to the bitmask. The OR operation allows us to set the correct bit, and the leftshift allows us to get the operand to use in the OR operation.
Full code:
bool checkIfPangramBitMap(std::string sentence) { int bitmap = 0x0; for (char c : sentence) { bitmap |= 0x1 << (c - 'a'); } return bitmap == 0x3FFFFFF;}
Benchmark
I used Perfbench to quickly benchmark the two code on a simple input 1000 times, with these results:
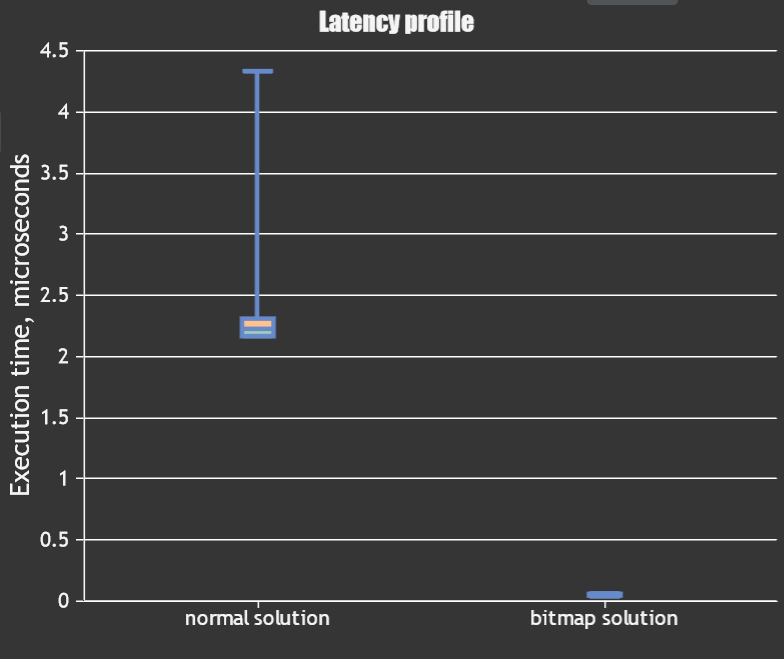

Note that the statistics are measured in microseconds.
As you can see, despite both sharing the same time complexity of O(n), the actual runtime tells us a different kind of story. Why is this the case?
The reason is fairly straight forward: The computer architecture instruction set usually has dedicated data processing operations (logical or arithmetic) baked in. For example, a logical OR statement between two values in ARM assembly instruction set might look like this:
ORR R0, R0, #0xFF
And we get our result straight away. In comparison, using something like an unordered_set probably involves a lot more overhead in terms of assembly instructions when trying to perform set operations.
Decompiling the two C++ solutions above into assembly, the bitmap solution had 657 lines while the set solution had a whopping 4506 lines! This explains the large gap in the runtime performance.
Closing Thoughts
We've seen that time complexity of a solution is not the whole story; often times, the performance will also differ based on the ground environment. Depending on the scope of your data, it may even be possible that a theoretically faster solution might have a slower runtime due overheads with its own data structures compared to a simpler solution with a bigger time compleixty.
The only sure-fire way to know is for us to run benchmarks to get undeniable proof that our solutions indeed give real, measurable performance gains.
Comments